This article brings to the table sample data of marketing campaigns in an imaginary online business for the purposes of learning, practicing, or testing software. The data will be in CSV, JSON, XLSX (Excel), and XML formats for you to choose from.
Overview
Here is a brief explanation of all columns (fields) in the dataset:
campaign_name: This column contains the name of the marketing campaignstart_date: This column contains the start date of the marketing campaignend_date: This column contains the end date of the marketing campaignbudget: This column contains the budget for the marketing campaign. It is a float between 1000 and 100000 with two decimal places.roi: This column contains the return on investment (ROI) of the marketing campaign. It is a float between -1 and 1 with two decimal places. ROI is usually calculated as(revenue - cost) / cost.type: This column contains the type of marketing campaign:email,social media,webinar, orpodcasttarget_audience: This column contains the target audience of the marketing campaign: B2C and B2B. B2B stands for business-to-business, and B2C stands for business-to-consumer.channel: This column contains the channel of the marketing campaign.conversion_rate: This column contains the conversion rate of the marketing campaign. The conversion rate is usually calculated as(number of conversions/number of visitors) * 100%.revenue: This column contains the revenue of the marketing campaign.
marketing-campaigns.csv
Below is the URL of the marketing-campaigns.csv file:
https://api.slingacademy.com/v1/sample-data/files/marketing-campaigns.csvYou can download the file to your local computer or read it programmatically with your favorite programming language like Python, Javascript, etc.
Here’s an example of how to do so with pandas (Python):
import pandas as pd
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
file_path = 'https://api.slingacademy.com/v1/sample-data/files/marketing-campaigns.csv'
dataframe = pd.read_csv(file_path, storage_options={
'User-Agent': 'Mozilla/5.0'})
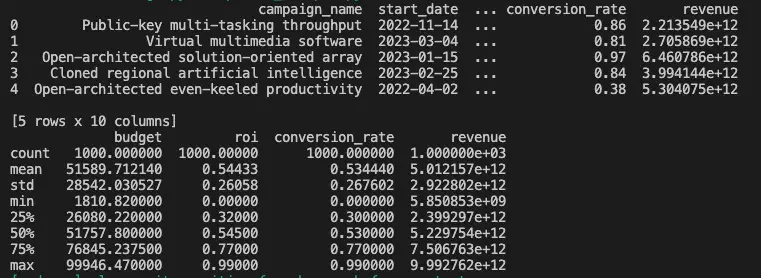
print(dataframe.head())
print(dataframe.describe())Output:
marketing-campaigns.json
You can manually download or send a GET request to our marketing-campaigns.json file at the URL below:
https://api.slingacademy.com/v1/sample-data/files/marketing-campaigns.jsonA part of the content (just two records) of the file will look like this:
{
"campaign_name": "Public-key multi-tasking throughput",
"start_date": "2023-04-01T00:00:00.000",
"end_date": "2024-02-23T00:00:00.000",
"budget": 8082.3,
"roi": 0.35,
"type": "email",
"target_audience": "B2B",
"channel": "organic",
"conversion_rate": 0.4,
"revenue": 709593.48
},
{
"campaign_name": "De-engineered analyzing task-force",
"start_date": "2023-02-15T00:00:00.000",
"end_date": "2024-04-22T00:00:00.000",
"budget": 17712.98,
"roi": 0.74,
"type": "email",
"target_audience": "B2C",
"channel": "promotion",
"conversion_rate": 0.66,
"revenue": 516609.1
},marketing-campaigns.xlsx
The URL to download the file is shown below:
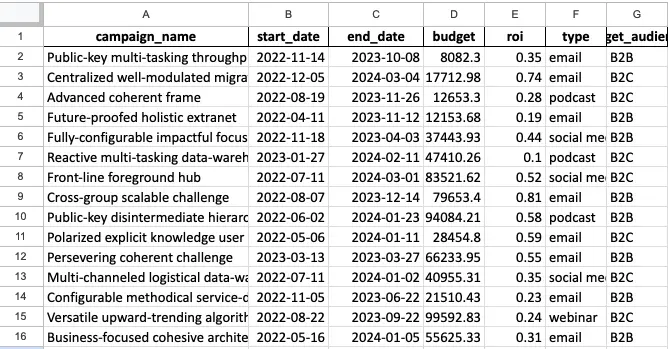
https://api.slingacademy.com/v1/sample-data/files/marketing-campaigns.xlsxAfter downloading the file, you can open it by using Microsoft Excel (Microsoft 365) or Google Sheets or something like that. The data will look like this:
marketing-campaigns.xml
You can get the file here:
https://api.slingacademy.com/v1/sample-data/files/marketing-campaigns.xmlAlthough XML files aren’t used as much these days, I think it’s still useful for someone in some cases.
Note: XML stands for eXtensible Markup Language. It is a markup language and file format for storing, transmitting, and reconstructing arbitrary data. It defines a set of rules for encoding documents in a format that is both human-readable and machine-readable.
Afterword
Please share your thoughts on our datasets by leaving comments. We’re more than happy to hear from you. Good luck & have a nice day!