Introduction
Pagination is a process of dividing a large amount of data into smaller chunks. It is important because it can improve the performance, usability, and security of your backend project. This article will walk you through 2 different ways (with 2 complete examples) to paginate in FastAPI. The first approach uses the page/per_page strategy and the second one uses the limit/offset strategy.
Live demo (with the limit/offset strategy):
https://api.slingacademy.com/v1/sample-data/users?offset=10&limit=20Prerequisites
To follow this tutorial, you should have at least some basic understanding of Python and FastAPI. If you don’t, please reach these articles first (at least):
- How to Setup Python Virtual Environments (venv)
- Write Your First Backend API with FastAPI (Hello World)
If you’re ready, just go ahead and see the important things (we’ll only use built-in features of FastAPI, no third-party packages are required).
Page/per_page pagination
This strategy uses two parameters: page and per_page. page indicates the current page number and per_page indicates how many items are displayed on each page. For example, if you have 1000 items and you set per_page to 10, then you will have 100 pages in total. To get the items for page 5, you would use the parameters page=5 and per_page=10.
To implement this strategy in FastAPI, you can use built-in features such as Query and Depends. Query is a class that allows you to define query parameters for your endpoint functions. Depends is a function that allows you to inject dependencies into your endpoint functions. For example, you can create a dependency function that returns the pagination parameters based on the query parameters.
Complete example:
# slingacademy.com
# main.py
from fastapi import FastAPI, Query, Depends, Response
from typing import List
# Create a FastAPI app
app = FastAPI()
# Define a list of 1000 dummy items
items = [f"Item {i}" for i in range(1, 1001)]
# Define a dependency function that returns the pagination parameters
def get_pagination_params(
# page must be greater than 0
page: int = Query(1, gt=0),
# per_page must be greater than 0
per_page: int = Query(10, gt=0)
):
return {"page": page, "per_page": per_page}
# Define an endpoint function that returns a paginated list of items
@app.get("/items", response_model=List[str])
def get_items(
response: Response,
pagination: dict = Depends(get_pagination_params),
):
# Get the page and per_page values from the pagination dictionary
page = pagination["page"]
per_page = pagination["per_page"]
# Calculate the start and end indices for slicing the items list
start = (page - 1) * per_page
end = start + per_page
# Send some extra information in the response headers
# so the client can retrieve it as needed
response.headers["x-total-count"] = str(len(items))
response.headers["x-page"] = str(page)
response.headers["x-per-page"] = str(per_page)
# Return a slice of the items list
return items[start:end]Start the app in the development mode:
uvicorn main:app --reloadGo to http://localhost:8000/docs in your web browser and test your work:
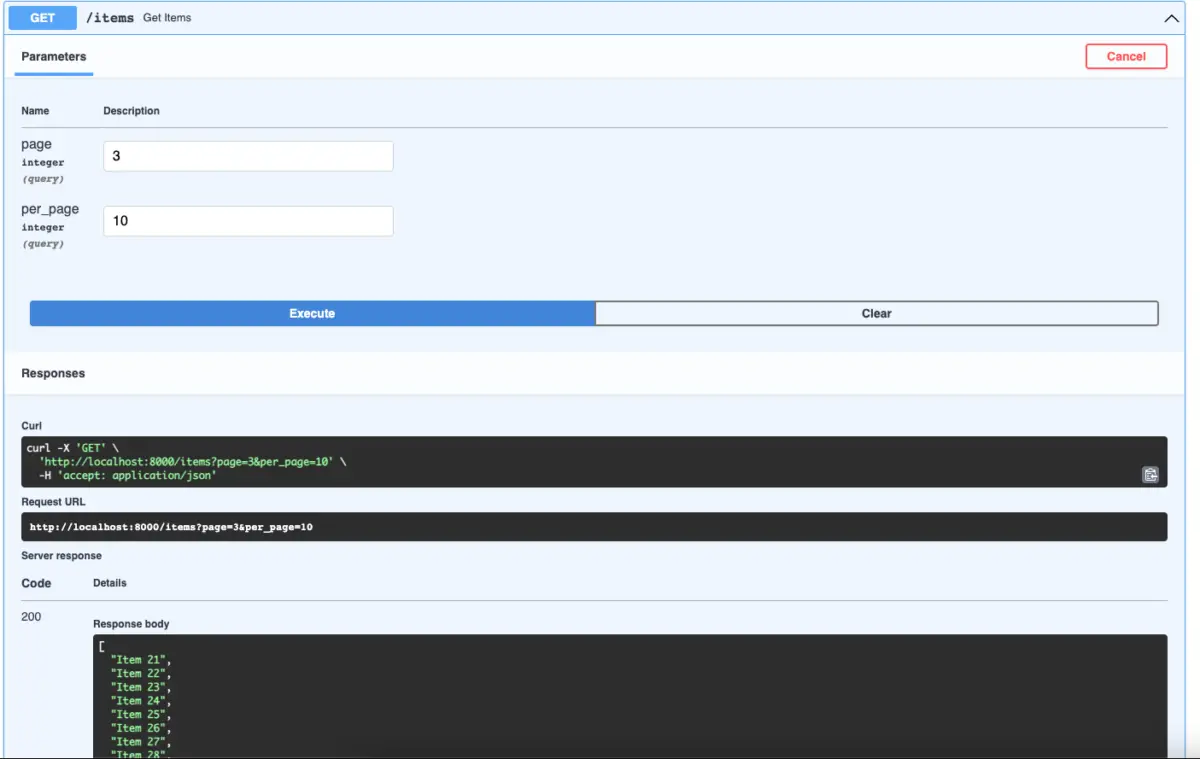
Limit/offset pagination
This strategy uses two parameters: offset and limit. offset indicates how many items to skip from the beginning of the dataset and limit indicates how many items to return after skipping. For instance, if you have 1000 items and you set offset to 40 and limit to 10, then you will get items from 41 to 50. There is not much difference between this strategy and page/per_page, but it gives more flexibility and control over the pagination.
To implement this strategy in FastAPI, you can use similar code as the preceding example but with different query parameters and calculations.
Complete example:
# slingacademy.com
# main.py
from fastapi import FastAPI, Query, Depends, Response
from typing import List
# Create a FastAPI app
app = FastAPI()
# Define a list of 1000 dummy items
items = [f"Item {i}" for i in range(1, 1001)]
# Define a dependency function that returns the pagination parameters
def get_pagination_params(
# offset must be greater than or equal to 0
offset: int = Query(0, ge=0),
# limit must be greater than 0
limit: int = Query(10, gt=0)
):
return {"offset": offset, "limit": limit}
# Define an endpoint function that returns a paginated list of items
@app.get("/items", response_model=List[str])
def get_items(
response: Response,
pagination: dict = Depends(get_pagination_params)):
# Get the offset and limit values from the pagination dictionary
offset = pagination["offset"]
limit = pagination["limit"]
# Calculate the end index for slicing the items list
end = offset + limit
# Add some headers to the response
# so the client can retrieve the total number of items, and other pagination info
response.headers["X-Total-Count"] = str(len(items))
response.headers["X-Offset"] = str(offset)
response.headers["X-Limit"] = str(limit)
# Return a slice of the items list
return items[offset:end]Once again, go to http://localhost:8000/docs to check your work (in a visual and convenient manner, thanks to the built-in Swagger docs of FastAPI):
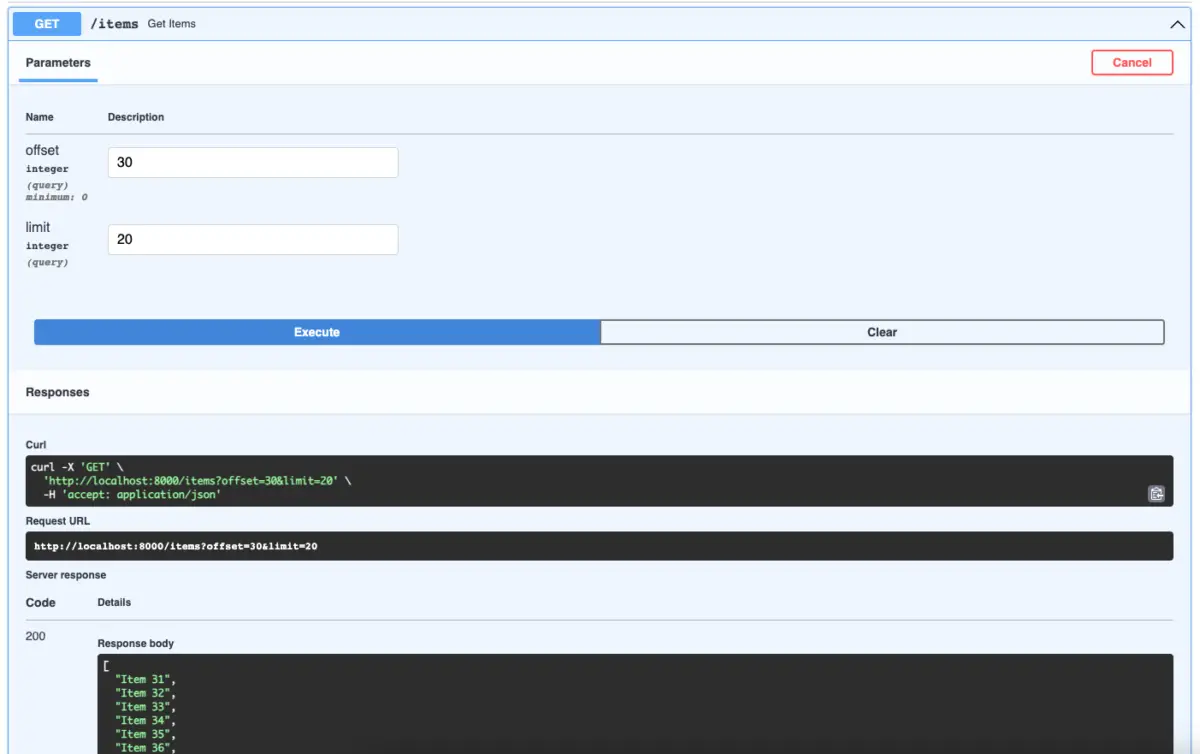
That’s it. You can improve the code and add some validation logic on your own to make the result even better and more secure. Happy coding & have a nice day!